以太网技术自诞生起,就以其简单易用和价格低廉的特点逐步成为局域网的主导技术。近年来,随着千兆、万兆以太网技术的相继应用,也促使网络运营商、设备制造商和标准化组织致力于将以太网技术向城域网和广域网领域推进。
以太网最初为局域网而设计,由于局域网本身已具备较高的可靠性和稳定性,因此在设计以太网之初并未建立管理维护的机制。而相对于局域网,城域网和广域网在链路长度和网络规模上都迅速扩大,于是有效管理维护机制的缺乏,已成为以太网技术在城域网和广域网应用的严重障碍。为此,在以太网上实现OAM机制成为必然的发展趋势。以太网OAM技术可以有效提高对以太网的管理和维护能力,保障网络的稳定运行。
图1 以太网OAM技术分级实现示意图
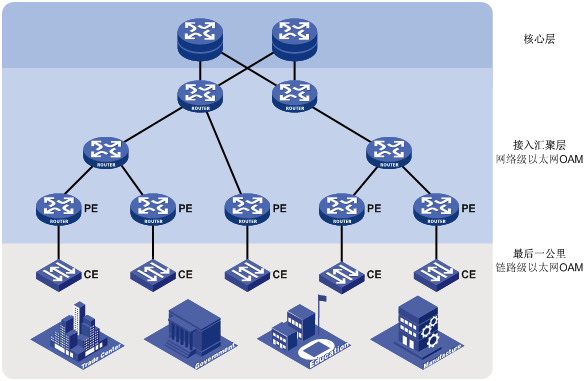
以太网OAM技术是分级实现的。如图1所示,以太网OAM技术分为以下两个级别:
l 链路级以太网OAM技术:多应用于网络的PE设备—CE设备—用户设备之间(也叫最后一公里)的以太网物理链路,用于监测用户网络与运营商网络之间的链路状态,典型协议为EFM OAM协议。
l 网络级以太网OAM技术:多应用于网络的接入汇聚层,用于监测整个网络的连通性、定位网络的连通性故障,典型协议为CFD协议。
各级别上典型的以太网OAM协议如表1所示。
表1 典型的以太网OAM协议
|
协议名称 |
应用级别 |
协议标准 |
说明 |
|
EFM OAM |
链路级 |
IEEE 802.3ah |
针对两台直连设备间的链路,提供链路性能监测、故障侦测和告警、环路测试等功能 |
|
CFD |
网络级 |
IEEE 802.1ag |
也称为CFM协议,主要用于在二层网络中检测链路连通性,确认故障并确定故障发生的位置 |
本文将对EFM OAM协议和CFD协议分别进行介绍。
2 EFM OAM技术实现
2.1 概念介绍
使能了EFM OAM功能的端口称为EFM OAM实体,简称OAM实体。
EFM OAM工作在数据链路层,其协议报文被称为OAMPDU。EFM OAM就是通过设备之间定时交互OAMPDU来报告链路状态,使网络管理员能够对网络进行有效的管理。
图2 OAMPDU报文格式示意图
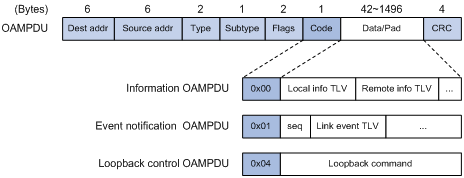
图2所示为OAMPDU的报文格式和常见的OAMPDU,OAMPDU中重要字段的含义如表2所示。
表2 OAMPDU重要字段含义
|
字段 |
含义 |
|
Dest addr |
目的MAC地址,为慢速协议组播地址:0x0180-C200-0002。慢速协议报文的特点就是不能被网桥转发,因此无论是否具备OAM功能或OAM功能是否激活,EFM OAM报文都不能跨多跳转发 |
|
Source addr |
源MAC地址,为发送端的端口MAC地址(若没有则采用该设备的桥MAC地址),是一个单播MAC地址 |
|
Type |
协议类型,为0x8809 |
|
Subtype |
协议子类型,为0x03 |
|
Flags |
Flag域,包含了EFM OAM实体的状态信息 |
|
Code |
消息编码,不同取值表示不同类型的OAMPDU,常见的OAMPDU如表3所示 |
表3 常见的OAMPDU
|
Code值 |
报文类型 |
中文含义 |
作用 |
|
0x00 |
Information OAMPDU |
信息OAMPDU,也称为心跳报文 |
用于在本端与远端的OAM实体之间交互各种状态信息(包括本地信息TLV、远端信息TLV和组织自定义信息TLV) |
|
0x01 |
Event Notification OAMPDU |
事件通知OAMPDU |
用于对连接本端与远端OAM实体的链路上所发生的故障进行告警 |
|
0x04 |
Loopback Control OAMPDU |
环回控制OAMPDU |
用于检测链路质量和定位链路故障,该报文中带有使能/去使能信息,用来开启/关闭远端环回功能 |
2.1.3 工作模式
EFM OAM的工作模式可分为主动模式和被动模式两种。EFM OAM连接只能由主动模式的OAM实体发起,而被动模式的OAM实体只能等待对端OAM实体的连接请求。都处于被动模式下的两个OAM实体之间无法建立EFM OAM连接。这两种模式下设备的处理能力如表4所示。
表4 两种工作模式下设备的处理能力
|
处理能力 |
主动模式 |
被动模式 |
|
初始化EFM OAM Discovery过程 |
可以 |
不可以 |
|
对EFM OAM Discovery初始化过程的响应 |
可以 |
可以 |
|
发送Information OAMPDU |
可以 |
可以 |
|
发送Event Notification OAMPDU |
可以 |
可以 |
|
发送不携带TLV的Information OAMPDU |
可以 |
可以 |
|
发送Loopback Control OAMPDU |
可以 |
不可以 |
|
对Loopback Control OAMPDU的响应 |
可以 |
可以 |
EFM OAM中定义的链路事件分为一般链路事件和紧急链路事件两大类。
1. 一般链路事件
一般链路事件用于链路性能监控,其包含的类型如表5所示。
表5 一般链路事件
|
事件类型 |
中文含义 |
描述 |
|
Errored Symbol Event |
错误信号事件 |
在单位时间内,错误信号的数量超过阈值 |
|
Errored Frame Event |
错误帧事件 |
在单位时间内,错误帧的数量超过阈值 |
|
Errored Frame Period Event |
错误帧周期事件 |
在收到指定数量帧的时间内,错误帧的数量超过阈值 |
|
Errored Frame Seconds Summary Event |
错误帧秒总数事件 |
在指定时间内,错误帧秒的数量超过阈值 |
l 错误帧周期事件的检测周期将被系统转换为某端口在该周期内能发送64字节帧的最大帧数,即以最大帧数作为周期,其计算公式为:最大帧数=接口带宽(bps)×错误帧周期事件的检测周期(ms)÷(64×8×1000)。
l 错误帧秒:如果在某一秒内发生了错误帧事件,该秒就被称为错误帧秒。
2. 紧急链路事件
紧急链路事件用于远端故障检测,其包含的类型以及对应的Information OAMPDU发送频率如表6所示。
表6 紧急链路事件
|
事件类型 |
中文含义 |
描述 |
OAMPDU发送频率 |
|
Link Fault |
链路故障 |
对端链路信号丢失 |
每秒发送一次 |
|
Dying Gasp |
致命故障 |
不可预知的本地故障发生,比如电源中断 |
不间断发送 |
|
Critical Event |
紧急事件 |
不明确的紧急事件发生,比如链路单通 |
不间断发送 |
2.2 运行机制
下面对EFM OAM的运行机制进行介绍。
EFM OAM功能的实现建立在EFM OAM连接的基础之上,EFM OAM连接的建立过程也称为Discovery阶段,即本端OAM实体发现远端OAM实体、并与之建立稳定对话的过程。
当设备的某个接口使能了EFM OAM功能时,如果该接口的EFM OAM工作模式为主动模式,便由该接口向对端发起EFM OAM连接。在建立EFM OAM连接的过程中,相连的OAM实体通过交互Information OAMPDU通报各自的EFM OAM配置信息。当OAM实体收到对端的配置参数后,决定是否建立EFM OAM连接。
图3 EFM OAM连接示意图

如图3所示,Device A的接口Ethernet1/1工作在主动模式下,当该接口上使能了EFM OAM功能时:
(1) Device A向Device B发送Information OAMPDU,其中包含Device A的EFM OAM配置信息。
(2) Device B收到该OAMPDU后,与自己的EFM OAM配置进行匹配,然后向Device A回复Information OAMPDU,其中除了包含Device A和Device B二者的EFM OAM配置信息外,还包含Device B对Device A的EFM OAM配置是否匹配的标志信息。
(3) Device A收到Device B发来的OAMPDU后,再来判断Device B的EFM OAM配置与自己的配置是否匹配。
通过以上过程,如果双方的EFM OAM配置都匹配,EFM OAM连接便建立起来。EFM OAM连接建立后,两端的OAM实体会周期性地发送Information OAMPDU来检测连接是否正常。如果一端OAM实体在连接超时时间内未收到对端发来的Information OAMPDU,则认为EFM OAM连接中断。
当一端OAM实体监控到一般链路事件时,将向对端OAM实体发送Event Notification OAMPDU进行通报,同时将监控信息记入日志并上报给网管系统;对端OAM实体收到该信息后,也将其记入日志并上报给网管系统。这样,管理员就可以通过观察日志信息动态地掌握网络的状况。
当设备上发生紧急链路事件而导致流量中断时,故障端OAM实体通过Information OAMPDU中的Flag域将故障信息(即紧急链路事件类型)通知给对端OAM实体,同时将故障信息记入日志并上报给网管系统;对端OAM实体收到该信息后,也将其记入日志并上报给网管系统。这样,管理员就可以通过观察日志信息动态地了解链路状态,对相应的错误及时进行处理。
远端环回功能是指主动模式下的OAM实体向对端(远端)发送除OAMPDU以外的所有其它报文时,对端收到该报文后直接将其环回给本端。它可用于定位链路故障和检测链路质量:网络管理员通过观察非OAMPDU报文的返回情况,可以对链路性能(包括丢包率、时延、抖动等)作出评判。
图4 远端环回示意图
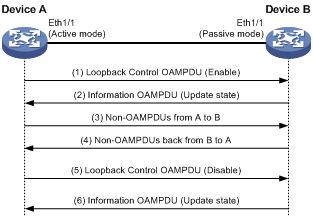
如图4所示,Device A的接口Ethernet1/1工作在主动模式下,在Device A与Device B之间的EFM OAM连接建立之后,使能该接口上的远端环回功能:
(1) Device A向Device B发送带有使能信息的Loopback Control OAMPDU,并等待回复。
(2) Device B收到该OAMPDU后,向Device A回复状态改变的Information OAMPDU,并进入环回状态(在此状态下,设备会把收到的非OAMPDU报文都按原路返回)。
(3) Device A收到回复后,开始向Device B发送非OAMPDU的测试报文。
(4) Device B收到测试报文后,将其按原路返回给Device A。
(5) 当Device A需要停止远端环回时,向Device B发送带有去使能信息的Loopback Control OAMPDU。
(6) Device B收到该OAMPDU后便退出环回状态,并向Device A回复状态改变的Information OAMPDU。
EFM OAM连接建立之后,两端的OAM实体会周期性地发送心跳报文(即Information OAMPDU)来检测连接是否正常。如果一端OAM实体在连接超时时间内未收到对端OAM实体发来的心跳报文,则认为OAM连接中断。
IEEE 802.3ah中定义了心跳报文发送周期为1秒,连接超时时间为5秒。H3C在协议规定的基础上,还允许用户对心跳报文的发送周期和连接超时时间进行配置。
维护域(MD)指明了连通错误检测所覆盖的网络,其边界是由配置在端口上的一系列维护端点所定义的。维护域以“维护域名”来标识。
为了准确定位故障点,在维护域中引入了级别(层次)的概念。维护域共分为八级,用整数0~7来表示,数字越大级别越高,维护域的范围也就越大。不同维护域之间可以相邻或嵌套,但不能交叉,且嵌套时只能由较高级别的维护域来嵌套较低级别维护域。低级别维护域的CFD PDU进入高级别维护域后会被丢弃;高级别维护域的CFD PDU则可以穿越低级别维护域;相同级别的维护域的CFD PDU不可以互相穿越。
图5 维护域嵌套示意图
在实际应用中,要对维护域进行合理规划:如图5所示,维护域MD_B嵌套在维护域MD_A中,要在MD_A中进行连通性检测,就要求MD_A的CFD PDU能够穿越MD_B,因此需要将MD_A的级别配置得比MD_B高。这样,MD_A的CFD PDU就可以穿越MD_B,从而实现了整个MD_A的连通性故障管理,而MD_B的CF PDU则不会扩散到MD_A中。
3.1.2 维护集
在维护域内根据需要可以配置多个维护集(MA),每个维护集是维护域内一些维护点的集合。维护集以“维护域名+维护集名”来标识。
一个维护集服务于一个VLAN,维护集中的维护点所发送的报文都带有该VLAN的标签,同时维护集中的维护点可以接收由本维护集中其它维护点发来的报文。
维护点(MP)配置在端口上,属于某个维护集,可分为维护端点(MEP)和维护中间点(MIP)两种。
1. 维护端点
维护端点以称为MEP ID的整数来标识,它确定了维护域的范围和边界。维护端点所属的维护集和维护域确定了该维护端点所发出报文的VLAN属性和级别。
维护端点的级别决定了其所能处理的报文的级别,维护端点所发出报文的级别就是该维护端点的级别。当维护端点收到高于自己级别的报文时,会将其按原有路径继续转发;而当维护端点收到小于或等于自己级别的报文时不会再转发,以确保低级别维护域内的报文不会扩散到高级别维护域中。
维护端点具有方向性,分为外向维护端点和内向维护端点两种。维护端点的方向表明了维护域相对于该端口的位置。其中,外向维护端点通过其所在端口向外发送报文,内向维护端点则不通过其所在端口向外发送报文,而是通过该设备上的其它端口向外发送报文。
2. 维护中间点
维护中间点位于维护域内部,不能主动发出CFD PDU,但可以处理和响应CFD PDU。维护中间点所属的维护集和维护域确定了该维护中间点所接收报文的VLAN属性和级别。
维护中间点可以配合维护端点完成类似于ping和tracert的功能。与维护端点类似,当维护中间点收到高于自己级别的报文时,会将其按原有路径继续转发;而当维护中间点收到小于或等于自己级别的报文时不会再转发,以确保低级别维护域内的报文不会扩散到高级别维护域中。
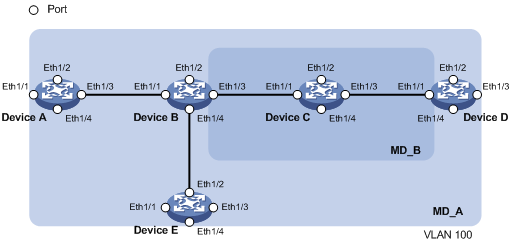
图6 维护点的分级配置
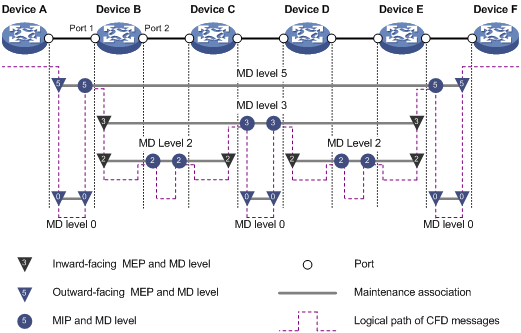
在图6所示的组网中,共有0、2、3、5四个级别的维护域,标识号较大的维护域的级别高、控制范围广;标识号较小的维护域的级别低、控制范围小。假设所有六台设备都只有两个端口,其中的一些端口作为不同级别维护域中的维护端点或维护中间点,譬如Device B的端口1上有以下维护点:级别为5的维护中间点、级别为3的内向维护端点、级别为2的内向维护端点和级别为0的外向维护端点。
CFD的协议报文被称为CFD PDU。不同的CFD PDU具有相同的报文头,通过头部的类型字段来区分报文类型。
图7 CFD PDU报文格式示意图
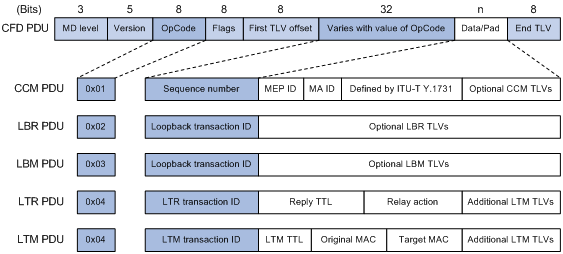
图7所示为CFD PDU的报文格式和常见的CFD PDU,CFD PDU中重要字段的含义如表7所示。
表7 CFD PDU重要字段含义
|
字段 |
含义 |
|
MD level |
维护域的级别,取值范围为0~7,取值越大表示级别越高 |
|
Version |
协议版本号,为0 |
|
OpCode |
消息编码,不同取值表示不同类型的CFD PDU,常见的CFD PDU如表8所示 |
|
Flags |
Flag域,该字段在不同类型的CFD PDU中表示不同的含义 |
|
Varies with value of OpCode |
Sequence number |
序列号,初始值为一个随机值,以后维护端点每发送一个CCM PDU,该字段的取值就会加1 |
|
Loopback transaction ID |
处理编号,初始值为0,以后维护端点每发送一个LBR/LBM/LTR/LTM PDU,该字段的取值就会加1 |
|
LTR/LTM transaction ID |
表8 常见的CFD PDU
|
OpCode值 |
报文类型 |
目的MAC地址 |
作用 |
|
0x01 |
CCM PDU |
01-80-C2-00-00-3x(组播地址,x的取值如表9所示) |
用于连续性检测,各维护端点均可发出 |
|
0x02 |
LBR PDU |
环回发起端的MAC(单播地址) |
用于环回,由环回对端回应 |
|
0x03 |
LBM PDU |
环回目的端的MAC(单播地址) |
用于环回,由环回发起端发出 |
|
0x04 |
LTR PDU |
链路跟踪发起端的MAC(单播地址) |
用于链路跟踪,由链路跟踪对端回应 |
|
0x05 |
LTM PDU |
01-80-C2-00-00-3y(组播地址,y的取值如表9所示) |
用于链路跟踪,由链路跟踪发起端发出 |
表9 目的MAC地址中x和y的取值
|
MD level |
x的取值 |
y的取值 |
|
7 |
7 |
F |
|
6 |
6 |
E |
|
5 |
5 |
D |
|
4 |
4 |
C |
|
3 |
3 |
B |
|
2 |
2 |
A |
|
1 |
1 |
9 |
|
0 |
0 |
8 |
3.2 运行机制
CFD的有效应用建立在合理的网络部署和配置之上。它的功能是在所配置的维护端点之间实现的,包括连续性检测功能(CC)、环回功能(LB)和链路跟踪功能(LT)三种。
连续性检测功能用来检测各维护端点之间的连通状态。其实现方式为:维护集内的各维护端点之间周期性地互发CCM PDU,通过分析报文内容和判断报文接收是否超时来检测链路当前的状态。若维护端点在3.5个CCM PDU发送周期内未收到远端维护端点发来的CCM PDU,则认为链路有问题,会输出日志报告,用户可以通过环回功能或链路跟踪功能来进行故障区间的定位。
维护端点发送的CCM PDU中Interval域的值与CCM PDU发送时间间隔、远端维护端点超时时间的关系如表10所示。
表10 Interval域的值与CCM PDU发送时间间隔、远端维护端点超时时间的关系
|
Interval域的值 |
CCM PDU发送时间间隔 |
远端维护端点超时时间 |
|
1 |
10/3毫秒 |
35/3毫秒 |
|
2 |
10毫秒 |
35毫秒 |
|
3 |
100毫秒 |
350毫秒 |
|
4 |
1秒 |
3.5秒 |
|
5 |
10秒 |
35秒 |
|
6 |
60秒 |
210秒 |
|
7 |
600秒 |
2100秒 |
环回功能类似于ping功能,通过发送测试报文和接收应答报文来检测源维护端点到目标维护端点是否可达。
图8 环回功能示意图
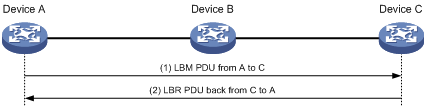
如图8所示,在Device A与Device C之间进行环回的过程如下:
(1) Device A向Device C发送LBM PDU,其中携带有该报文的发送时间;
(2) Device C收到该报文后,回复LBR PDU给Device A,其中携带有LBM PDU的发送和接收时间,以及LBR PDU的发送时间。
在超时时间内,如果Device A收到了Device C回应的LBR PDU,则可以根据其中携带的时间信息算出Device A到Device C的网络时延;否则,便认为Device A到Device C不可达。此外,通过连续发送多个LBM PDU并观察LBR PDU的返回情况,还可以了解网络的丢包情况。
链路跟踪功能类似于Tracert功能,通过发送测试报文和接收应答报文来查看源维护端点到目标维护端点之间的路径或定位故障点。
图9 链路跟踪功能示意图
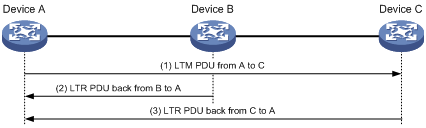
如图9所示,在Device A与Device C之间进行链路跟踪的过程如下:
(1) Device A向Device C发送LTM PDU,其中携带有TTL值和目标维护端点的MAC地址;
(2) Device B收到该报文后,先将其TTL值减1,再继续转发给Device C,并回复LTR PDU给Device A,其中也携带有TTL值(等于Device A发送来的LTM PDU中的TTL值减1);
(3) Device C收到该报文后,回复LTR PDU给Device A,其中也携带有TTL值(等于Device B转发来的LTM PDU中的TTL值再减1)。由于根据LTM PDU中携带的目标维护端点的MAC地址,Device C可以判断出自己就是目标维护端点,因此不会再转发该报文。
如果Device A到Device C之间的路径有故障,则故障点下游的设备将无法收到LTM PDU,也不会回复LTR PDU,据此可判定故障点的位置。例如,若Device A能收到Device B回复的LTR PDU,但收不到Device C回复的LTR PDU,就可以判定Device B和Device C之间的路径有故障。
3.3 H3C实现的技术特色
由于CCM PDU的发送周期跨度很大,从3.3毫秒到10分钟。但是,3.3毫秒的CCM PDU发送周期会对业务板上其它业务的性能产生影响,而其它业务对CPU的抢占也会影响CCM PDU的发送精度。因此,H3C可采用单独的辅助CPU来处理这种快速报文的发送和接收,检测结果通过主CPU之间以及主CPU与辅助CPU之间的通信来通知维护端点所在的业务板。
Smart Link实现了主备链路的冗余备份和快速迁移。在双上行组网中,当主用链路出现故障时,设备自动将流量切换到备用链路,这样就实现了主备链路的冗余备份。但是,对于传输链路上的设备或链路自身发生的故障(如光纤链路发生单通、错纤、丢包等故障)以及此类故障的恢复,Smart Link本身是无法感知的。
H3C通过将Smart Link与CFD协议的连续性检测功能进行联动,可以对上述故障的发生或恢复进行检测。其原理如下:维护端点周期性地发送CCM PDU,同一维护集内的其它维护端点收到该报文后便能获知远端维护端点的状态。若维护端点在3.5个发送周期内仍未收到该报文,便认为链路有问题,于是通知Smart Link重新计算Smart Link的链路状态,以便进行链路切换。
H3C支持LTM PDU的自动发送,即:当本端维护端点在3.5个CCM PDU发送周期内未收到远端维护端点发来的CCM PDU时,便判定与远端维护端点的连接中断,本端维护端点会自动发送LTM PDU,并通过检测回应的LTR PDU来定位故障。这个过程也会被记录下来,使网络管理员可以在事后查看故障的时间和路径等信息。
4 典型组网应用
图10 以太网OAM典型应用组网图
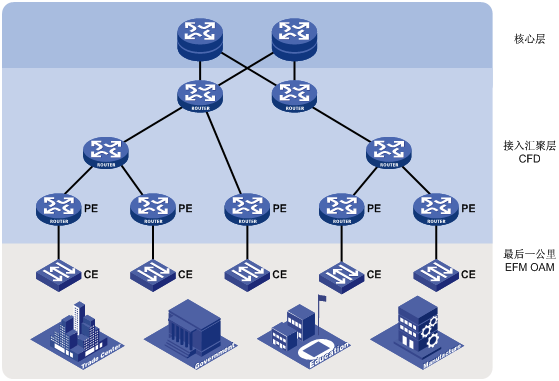
以太网OAM在城域网的典型应用如图10所示,可分为以下两个层次进行部署:
l 在CE设备与PE设备之间的链路上部署EFM OAM:通过CE设备与PE设备之间定时互发Information OAMPDU来检测用户业务接入链路的连通性。网络管理员可以通过观察错误帧的情况,来判断CE设备与PE设备之间链路的性能;通过远端环回功能可以检测链路的质量,或在发生链路故障时进行故障定位。
l 在接入汇聚层的网络中部署CFD:先根据设备所属的ISP来划分维护域,把同一ISP管理下的设备划分在同一维护域中;再根据业务来划分维护集,使每个维护集对应一个VLAN。CFD通过维护集内的各维护端点定时互发CCM PDU来检测维护集内网络的连通性。当检测到连通性故障后进行报警,网络管理员可以通过环回功能或链路跟踪功能进行故障定位或路径查找。

